Mapping Overlaps in Benchmarks through Perplexity in the Wild
Siyang Wu*, H. Bao*, S. Li*, Ari Holtzman, and James A. Evans
ICLR 2026. Rated among the top ~2% of all submissions, 2025
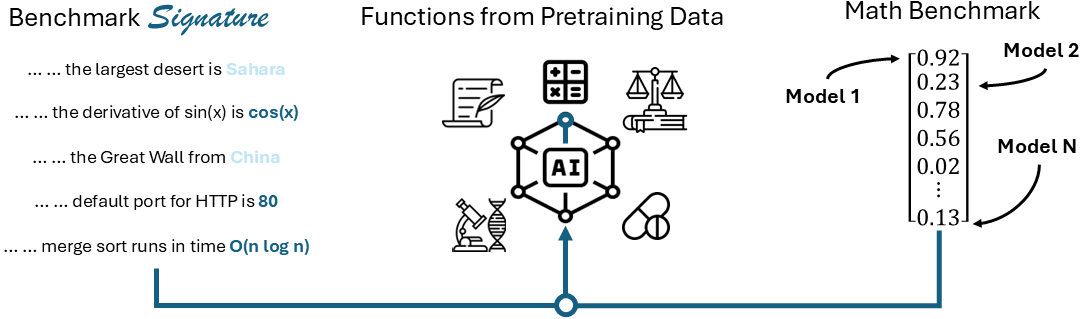
We develop signatures of capacity familiarity to characterize large language model (LLM) benchmarks and their meaningful overlaps. Benchmark signatures probe the capacity required for benchmark performance. We formally define them as a set of salient tokens drawn from in-the-wild, naturally authored corpora, where LLM token perplexity, reflecting more or less pre-training exposure, becomes highly predictive of LLM benchmark performance. Through a large-scale meta-evaluation, we extract benchmark signatures via stepwise forward selection with linear regressions across 32 LLMs and 88 benchmarks spanning diverse knowledge, coding, logic, instruction following, math, language, reasoning, and world modeling. Our analysis situates signatures in relation to...... Read more
How Do Language Models Generate Slang: A Systematic Comparison between Human and Machine-Generated Slang Usages
Siyang Wu and Zhewei Sun
EMNLP 2025 Findings (to appear), 2025
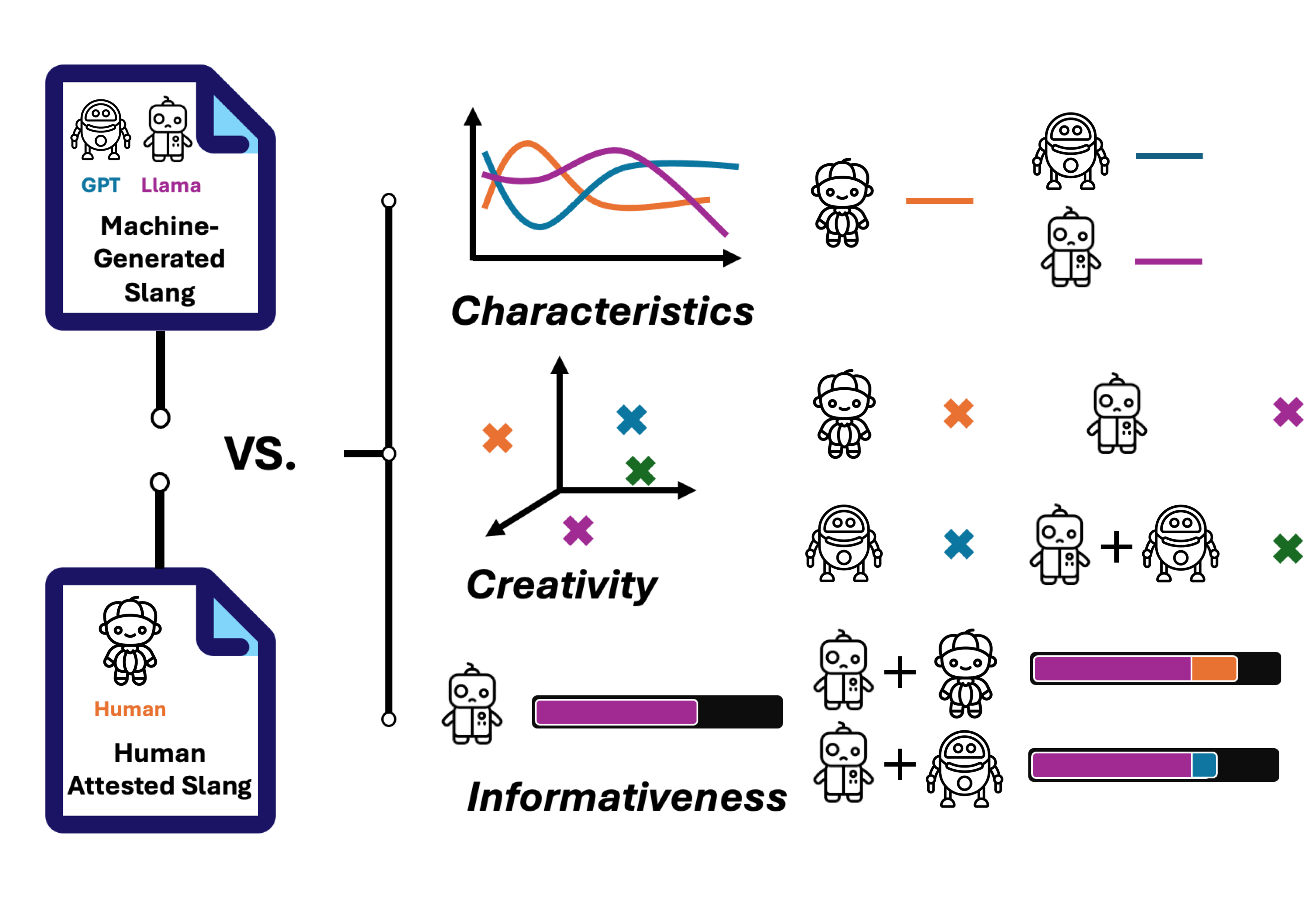
Slang is a commonly used type of informal language that poses a daunting challenge to NLP systems. Recent advances in large language models (LLMs), however, have made the problem more approachable. While LLM agents are becoming more widely applied to intermediary tasks such as slang detection and slang interpretation, their generalizability and reliability are heavily dependent on whether these models have captured structural knowledge about slang that align well with human attested slang usages. To answer this question, we contribute a systematic comparison between human and machine-generated slang usages. Our evaluative framework focuses on three core aspects: 1) Characteristics of...... Read more
Language Models Surface the Unwritten Code of Science and Society
H. Bao, Siyang Wu, J. Choi, Y. Mao, and James A. Evans
arXiv preprint, 2025
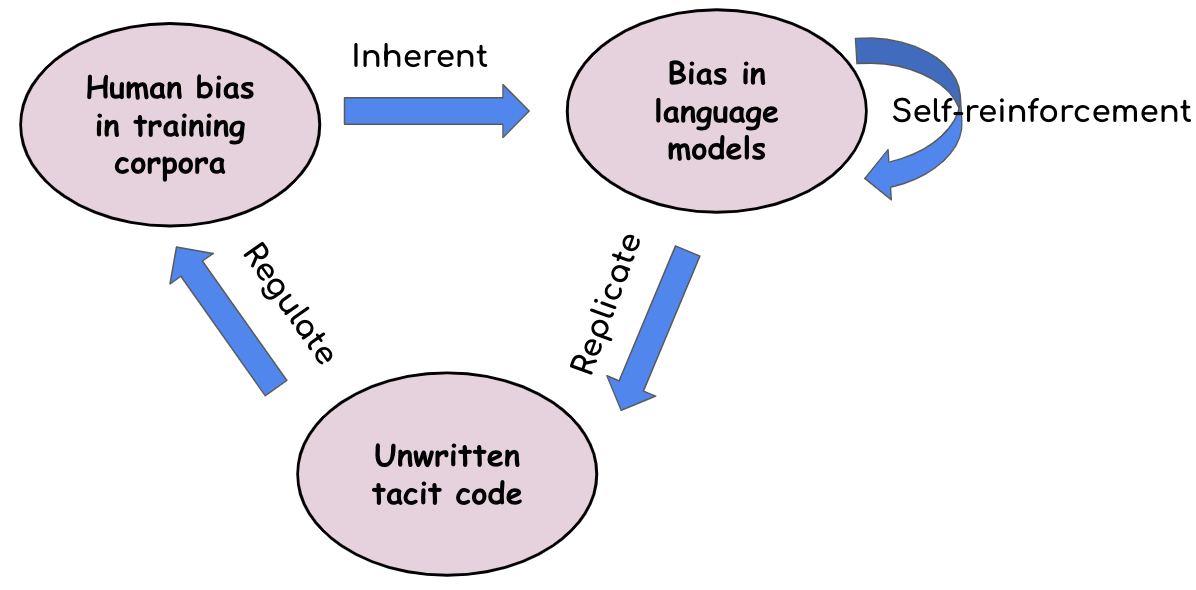
This paper calls on the research community not only to investigate how human biases are inherited by large language models (LLMs) but also to explore how these biases in LLMs can be leveraged to make society’s “unwritten code” - such as implicit stereotypes and heuristics - visible and accessible for critique. We introduce a conceptual framework through a case study in science: uncovering hidden rules in peer review - the factors that reviewers care about but rarely state explicitly due to normative scientific expectations. The idea of the framework is to push LLMs to speak out their heuristics through generating...... Read more
Automatically Advancing LLM Expertise in Technology Judgment
Siyang Wu, H. Bao, N. Kunievsky, and James A. Evans
arXiv preprint, 2025
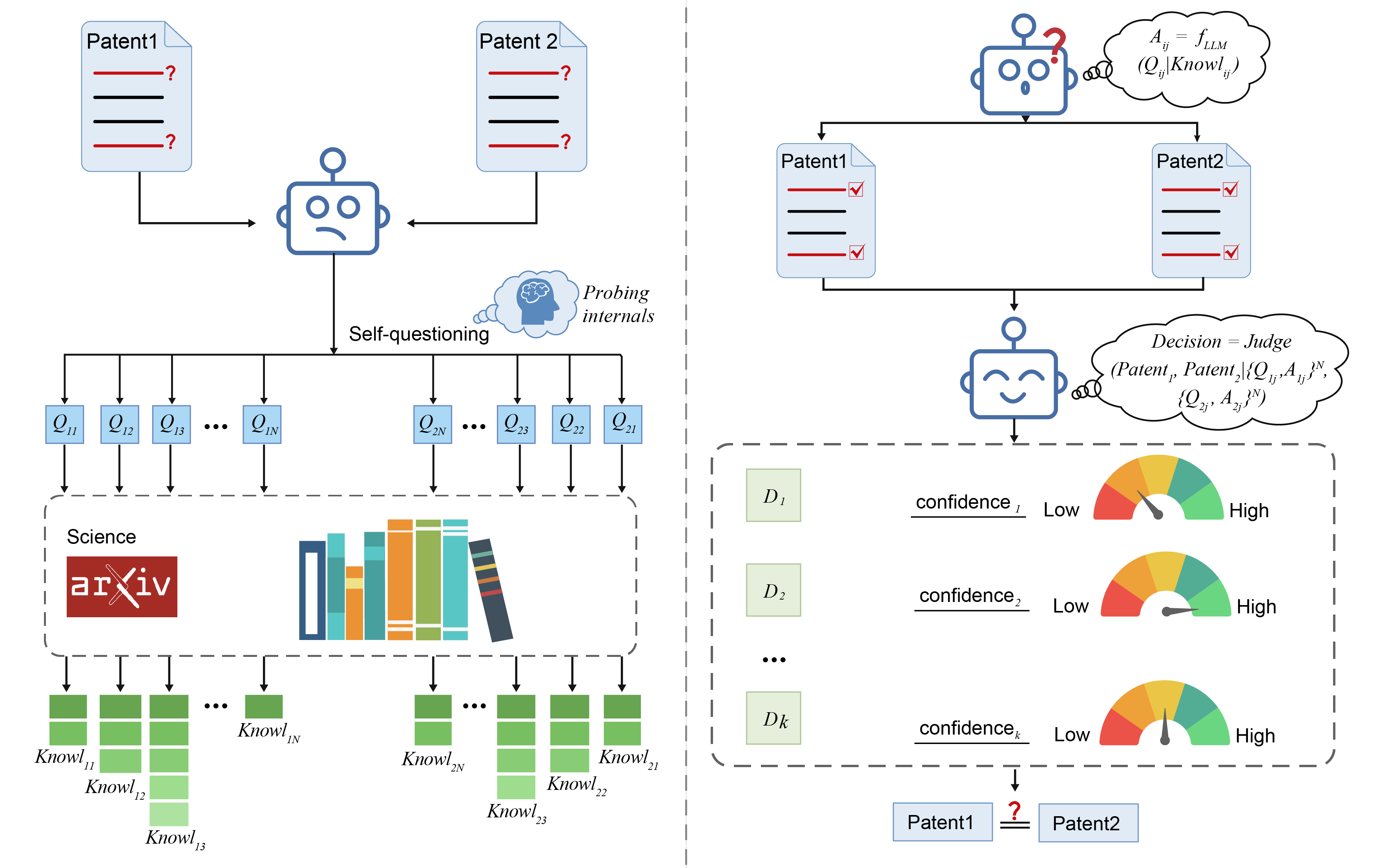
Large language models (LLMs) are rapidly becoming core tools for science, engineering, and innovation. Their promise lies not just in remembering facts, but in putting knowledge to work. Despite their impressive ability to answer increasingly difficult questions, it remains unclear whether LLMs truly use their knowledge when confronted with new and challenging tasks. We address this question with a patent classification task that requires deep conceptual understanding: distinguishing objectively different but semantically similar patents. To evaluate this approach, we introduce a challenging new benchmark of 1.3 million post-2015 computer science patent pairs, characterized by dense technical jargon and strategically complex...... Read more